
Breaking News


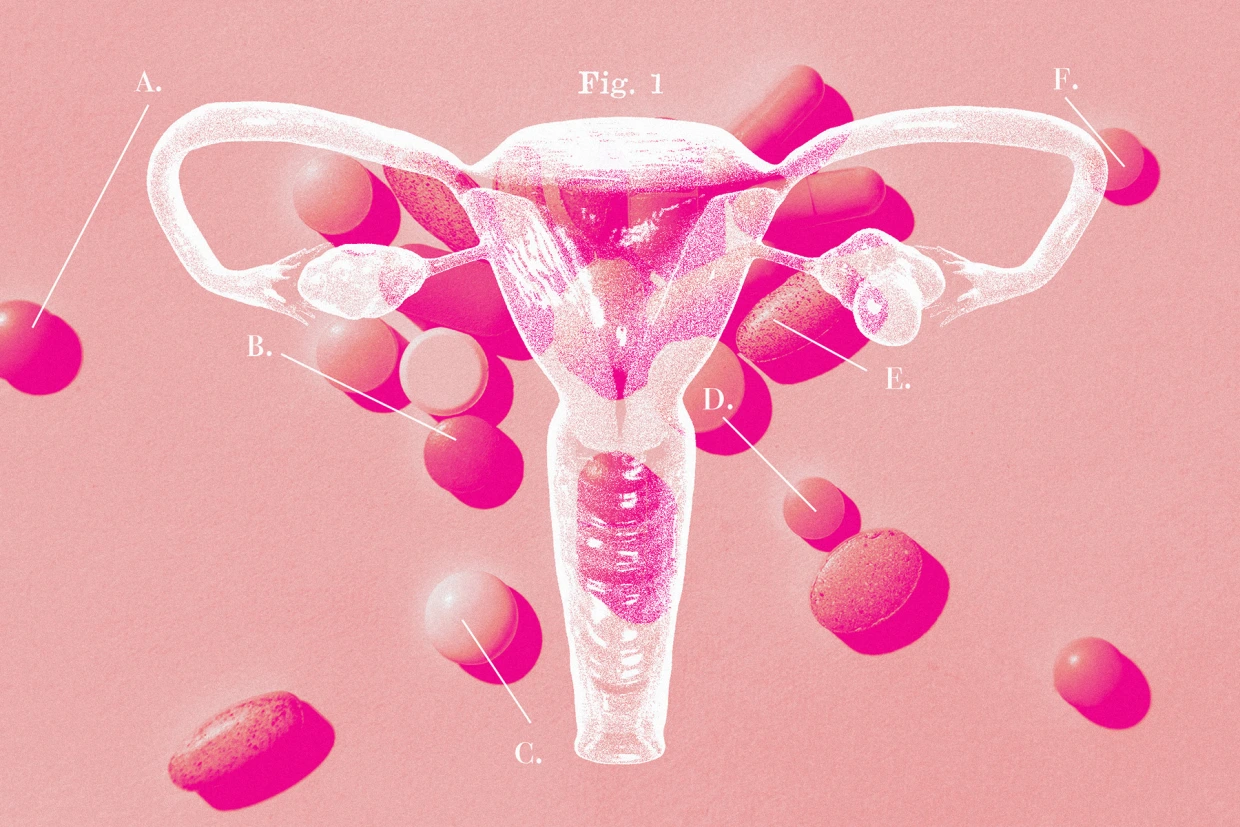
PCOS symptoms are still difficult for doctors to diagnose and treat. Here’s why
Every morning, Jeni Gutke swallows 12 pills. In the evening, she takes…

Here Are 10 Things People Immediately Notice When You Have Guests Over, And 5 They Couldn’t Care Less About
Having people over at your house, whether it's for a casual get-together…

5 Sneaky Signs You Have Insulin Resistance, According to Dietitians
Four out of 10 adults between the ages of 18 and 44…

Ewan McGregor says he had an intimacy coordinator for sex scenes with his wife
Hollywood star Ewan McGregor has said it was “still necessary” to have an intimacy…

The 8 Foods You Should Focus On for Better Health, According to a Gastroenterologist
Reviewed by Dietitian Emily Lachtrupp, M.S., RD One of our favorite gut…
